Graduate Project
Try it out!#
Below are two React components that will let you interact with the trained models. Give it a try, then read on to find out how they were applied!
caution
The classifier models are running on my local Raspberry Pi 4 and take around 30s for each request. Thanks!
Classifier#
Enter any text (up to 500 characters) into the input box and click Query! to get the model's scores. The numbers can be used as probabilities or converted to binary classifications using a threshold value.
Semantic Similarity#
Enter any text (up to 500 characters) into the two input boxes and click Query! for each to load the respective sentence embedding. After both sentence embeddings have been queried, the cosine similarity will be displayed.
tip
To see the returned vector embeddings open the console!
Chrome: CTRL+SHIFT+I Firefox: CTRL+SHIFT+K
Concept#
The concept behind my project was to create a 3rd party content moderation system that could be used by any website or service that has user generated text content. Due to the increased rates of user generated content appearing on services today, the companies running these services need a proactive, accurate, and streamlined approach to moderating it. The project involved using 3 neural networks to classify the text as as toxic, offensive, or hate speech. The client could then use threshold options to determine classifications and processing. If the scores were within either the autoflag threshold (inappropriate content) or autosafe threshold (appropriate content), the result was returned to the client immediately. If the result was between those two, the text would be forwarded to a set of human moderators who could provide further classification.
But why human moderators? With the limitations of current technology, language is constantly evolving, its heavy reliance on context for understanding, it is difficult to say whether something is offensive or not. To avoid situations where we might classify something as toxic when it is a tongue-in-cheek joke, human moderators are our last and most effective resort. It's not a total loss, however, because human moderators can help create and improve datasets going forward by tagging data and spans in the text with more nuanced classifications. This could help reinforce and expand the classifier capabilities.
The second application of machine learning I used was semantic similarity analysis. This was accomplished using the S-BERT library to generate vector representations of the input texts. These vectors could then be compared using cosine similarity to get a score between 0 and 1, where 0 represents no (semantic) similarity and 1 representing maximal (semantic) similarity. Allowing for semantic search within the previously seen texts provided a more robust way to make recommendations to moderators, as the system would not only be limited to searching for items with similar words.
note
A high semantic similarity does not necessitate similar meaning. For example, "i hate x" and "i love x" will have a high semantic similarity because they both talk about the same thing (soda), have the same subject (I), and contain strong emotion words (love/hate) for verbs.
ML Models#
The purpose of the machine learning models is to provide a binary classification in an attempt to positively identify three separate categories of inappropriate text: hate speech, offensiveness, and toxicity. To accomplish this task I leveraged a pre-trained neural network known as BERT. This model was developed by Google in 2018 and pre-trained on the BooksCorpus dataset with 800 million words and the English Wikipedia with 2500 million words.
Using pre-trained models to bootstrap the training process is known as transfer learning and has been widely used in computer vision applications since the development of deep residual networks. Like vision, language shares a large number of constructs that can be learned and transferred between models. This became possible after the development of the transformer architecture. After bootstrapping the model with the pre-trained weights, it is possible to fine-tune the model for better accuracy.
Datasets#
| Model | Dataset | Records |
|---|---|---|
| Hate Speech | Automated Hate Speech Detection and the Problem of Offensive Language | ~47,000 |
| Offensive Language | Multilingual Offensive Language Identification in Social Media | ~9m |
| Toxic Language | Jigsaw Unintended Bias in Toxicity Classification | ~2m |
Architecture#
Overview#
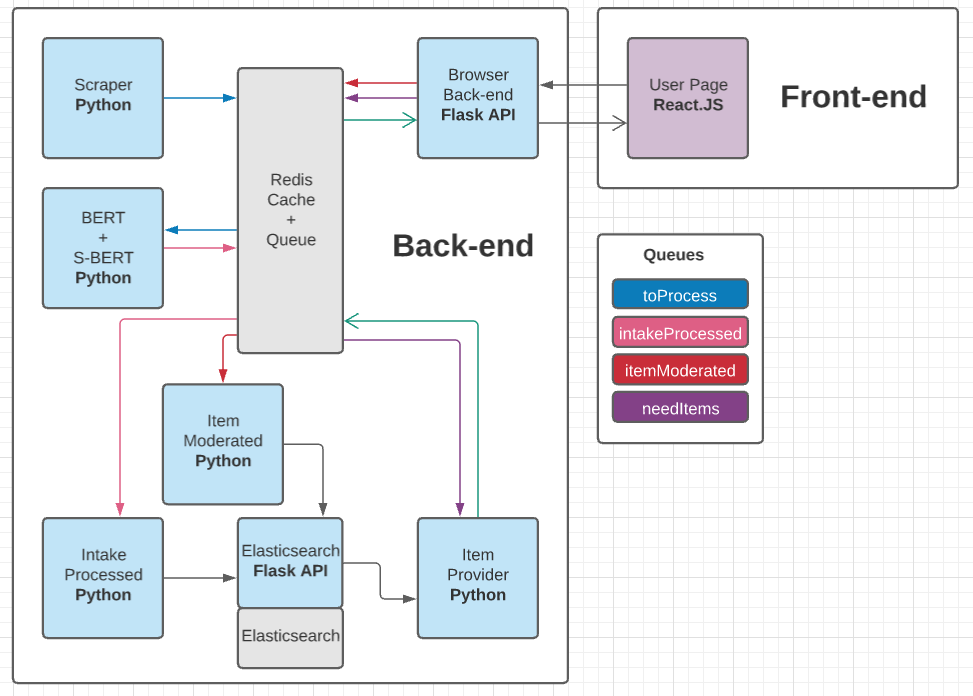
I chose to use an event-driven architecture for this project. Although the initial setup is more complex, I feel that the future flexibility and modularity of a microservice architecture are worth it through the lifetime of a project. Designing a system in this way allows for benefits such as improved scalability, a more agile development cycle, and fault tolerance throughout the system.
To orchestrate the system, I used Kubernetes and Docker. Containerizing each service made it really easy to move them around between different machines without having to worry about different host operating systems or hardware. Kubernetes is an absolute workhorse. It made it very easy to deploy and link all services in a modular way without doing a lot of hard coding configuration. All of the Kubernetes yaml files and Dockerfiles are available on github.
I used Redis for the event bus, with all event producers and consumers reading and writing JSON to Redis lists (utilized as queues). This design made it very easy to debug the system as any errors were be thrown in their respective Kubernetes pod and the dataflow was visible in Redis. Because events are fire-and-forget, each service can get back to work immediately without having to wait for a response.
Services#
| BERT + S-BERT |
|---|
| Classify the received item’s text using three binary classifiers for hate speech, offensiveness, and toxicity. Generate a semantic-embedding vector that can be compared to other vectors to rank items by their similarity in meaning. |
| Browser-Backend-API |
|---|
| Main interface between front-end and back-end. The front-end can make GET requests to get a new batch of items to moderate. The front-end can make POST requests to send the results of item moderation. |
| Intake-Processed |
|---|
| Finalizes processing of new items by setting default values and any other preprocessing necessary. Then writes the item to the relevant databases (in this case elasticsearch) via their REST APIs. |
| Item-Moderated |
|---|
| Finalizes processing of moderated items by doing any necessary preprocessing, then writes the item to the relevant databases (in this case elasticsearch) via their REST APIs. |
| Task-Provider |
|---|
| Queries the elasticsearch REST API for a batch of new items to be sent to a moderator for moderation. It writes the batch to Redis, where the backend-api can fetch them at a later time. |
| Elasticsearch-API |
|---|
| Provides an abstraction layer in front of the elasticsearch database providing end-points for creating, reading, and updating items in the database. |